100% баталгаатай үр дүн өгдөг хиймэл оюуны математик систем бий боллоо.

2024 оны Олон улсын математикийн олимпиадын үеэр нэг “оролцогч” мөнгөн медалийн болзол хангасан амжилт үзүүлжээ. Гэвч нэг л зүйл саад болсон нь хүн биш, хиймэл оюуны систем байсан юм. Ингэснээр AI нь тус тэмцээний түүхэнд анх удаа медалийн түвшний гүйцэтгэл үзүүлсэн тохиолдол болжээ. Nature сэтгүүлд нийтлэгдсэн өгүүлэлд судлаачид энэ гайхамшигт амжилтын ард буй технологийн шийдлүүдийг дэлгэрэнгүй тайлбарлажээ. Энэ хиймэл оюун ухаан нь AlphaProof бөгөөд Google DeepMind компани хөгжүүлсэн, нарийн математик асуудлуудыг шийдэхийг сурдаг дэвшилтэт программ юм. Олимпиадын үеэр үзүүлсэн амжилт нь өөрөө гайхалтай боловч AlphaProof-ийг үнэхээр онцгой болгодог зүйл нь алдааг олох, засах чадвар нь юм. Том хэлний загварууд (LLM) математикийн бодлого бодож чаддаг ч тэдний хариулт бүрэн үнэн болохыг баталгаажуулах боломжгүй байдаг. Логикт далд алдаа нуугдаж байж болно.
AlphaProof-ийг онцгой болгож байгаа зүйл нь түүний хариулт үргэлж 100% зөв байдагт оршдог. Үүний шалтгаан нь AlphaProof нь Lean хэмээх тусгай програмчлалын орчныг ашигладагт оршино (анх Microsoft Research-д хөгжүүлсэн). Энэ орчин нь логикийн бүх алхмыг хатуу багш шиг шалгадаг. Өөрөөр хэлбэл, компьютер өөрөө хариултыг баталгаажуулдаг учир түүний дүгнэлтэд бүрэн итгэж болно.
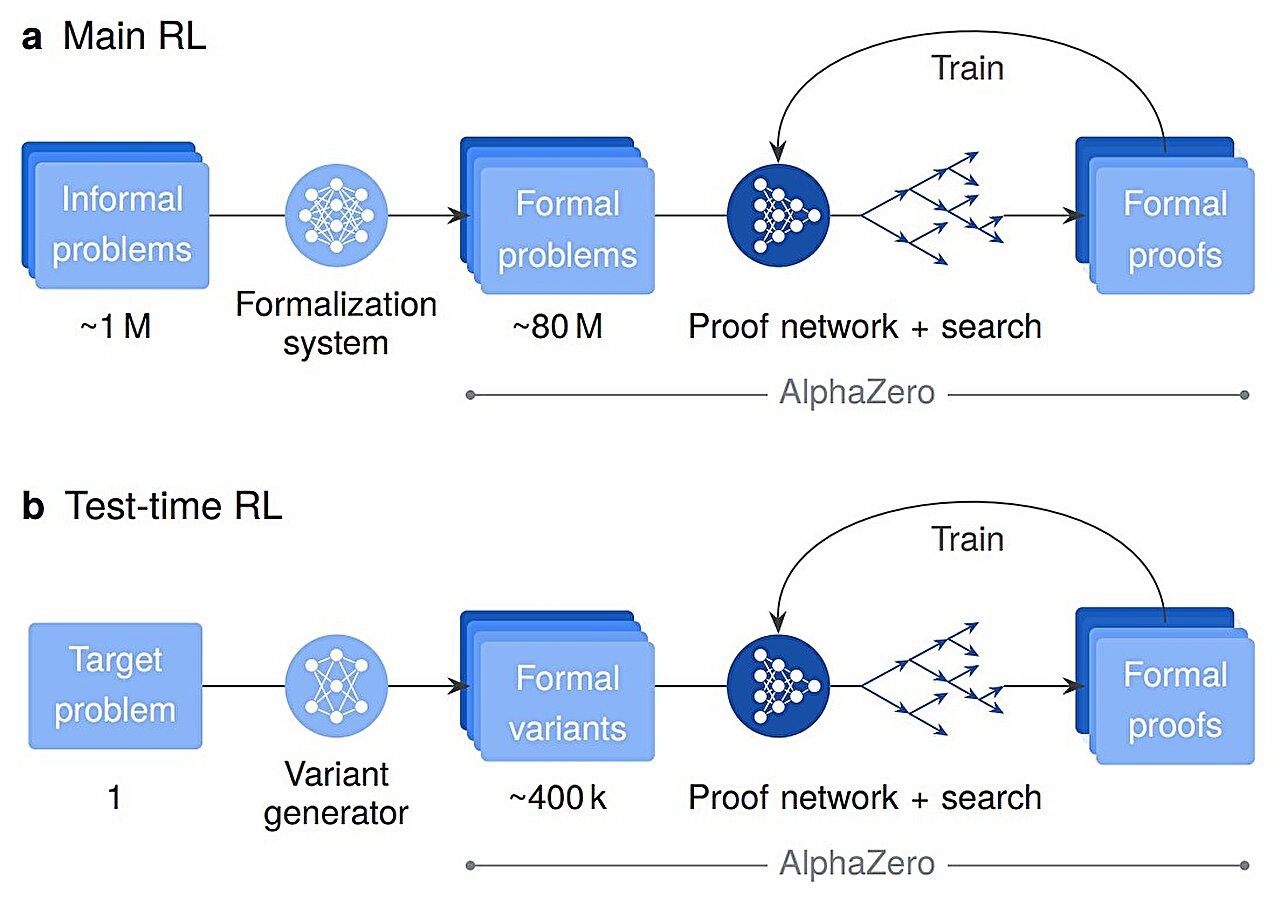
Зураг1. AlphaProof-ийн суралцах болон дасан зохицох процессууд
Гурван үе шаттай сургалтын процесс
Энэ хүчирхэг системийг дээд түвшний логик сэтгэлгээтэй болгохын тулд гурван шаттай сургалт явуулжээ.
Эхний шатанд судлаачид AlphaProof-д логик, математик хэл, программчлалын бүтэц зэрэг ойлголтыг өргөн хүрээнд олгохын тулд ерөнхий код болон математик текстээс бүрдэх ойролцоогоор 300 тэрбум токен өгөгдөл өгсөн байна.
Дараагийн шатанд Lean орчинд бичигдсэн 300,000 мэргэжлийн математик нотолгоо ашиглан системийг нарийн төвөгтэй нотолгоотой танилцуулжээ.
Эцсийн шатанд систем өөрөө бие даан асуудал шийдвэрлэхийг сурсан. Түүнд 80 сая албан ёсны математик бодлого бүхий аварга хэмжээний “даалгавар” өгсөн байна. Туршилт–алдааны зарчимд суурилсан бататгах сургалт (Reinforcement Learning, RL)-ыг ашиглан AlphaProof нь амжилттай нотолгоо бүрийн төлөө шагнал авсан. Ийм том хэмжээний бодлого шийдсэнээр систем нь хүний жишээг дуурайхаас давсан, шинэ, нарийн төвөгтэй логик стратегиудыг өөрөө бүтээж сурсан байна.
Хамгийн хүнд бодлогуудын хувьд AlphaProof судлаачдын бүтээсэн Test-Time RL (TTRL) хэмээх аргыг ашигласан. Энэ арга нь зорилтот бодлогын сая сая хялбаршуулсан хувилбарыг үүсгэн бодож, эцэст нь зөв хариунд хүрдэг.
“Манай ажил нь бодит туршлагад тулгуурлан өргөн цар хүрээтэй сургалт хийснээр өндөр төвшний математик сэтгэлгээтэй системүүдийг бүтээж байгааг харуулж байна. Энэ нь нарийн төвөгтэй математик бодлого шийдэх найдвартай AI хэрэгсэл хөгжүүлэх замыг нээж байна” гэж судлаачид өгүүлэлдээ бичжээ.Үүнээс гадна AlphaProof нь шийдэхэд бараг боломжгүй мэт санагдах математик бодлогуудыг бодохын зэрэгцээ, математикчдад өөрсдийн ажлыг засах болон шинэ онол боловсруулахад туслахад ашиглагдаж болно.
Эх сурвалж:
- Thomas Hubert et al, Olympiad-level formal mathematical reasoning with reinforcement learning, Nature(2025).
- https://phys.org/news/2025-11-ai-math-genius-accurate-results.html
Мэдээ бэлтгэсэн : Б.Дөлгөөнтуяа /Математикийн салбарын эрдэм шинжилгээний ажилтан/
Бусад мэдээлэл
